Introduction
kgrams provides R users with a set of tools for
training, tuning and exploring
-gram
language models1. It gives support for a number of common
Natural Language Processing (NLP) tasks: from the basic ones, such as
extracting (tokenizing)
-grams
from a text and predicting sentence or continuation probabilities, to
more advanced ones such as computing language model perplexities 2 and
sampling sentences according the language model’s probability
distribution. Furthermore, it supports many classical
-gram
smoothing methods, including the well-known modified Kneser-Ney
algorithm, first described in (Chen and Goodman
1999), and widely considered the best performing smoothing
technique for
-gram
models.
-gram
language models are notoriously demanding from the space point of view,
and many of the toolkits available for
-gram
based NLP employ various techniques and data structures to achieve the
data compression required by the large scales of industry (and,
sometimes, academic) applications (see (Pibiri
and Venturini 2019) for a recent review). On the other hand, at
such large scales, neural language models are often the most
economic and best performing choice, and this is likely to become more
and more so in the future. In developing kgrams, I made no
special attempt at data compression, and
-grams
and count estimates are stored in plain C++ STL hash-tables, which can
grow rapidly large as the size of corpora and dictionaries
increases.
On the other hand, most focus is put on providing a fast,
time efficient implementation, with intuitive interfaces for text
processing and for model evaluation, and a reasonably large choice of
pre-implemented smoothing algorithms, making kgrams
suitable for small- and medium-scale language model experiments, for
rapidly building baseline models, and for pedagogical purposes.
In my point of view, the interest in
-gram
language models is mainly pedagogical, as they provide very simple
algorithms (together with all their limitations) for learning a natural
language’s sentence probability distribution. Nonetheless, and for the
same reasons,
-gram
models can also provide a useful, quick baseline for model building with
more complex algorithms. An R implementation of classical
-gram
smoothing techniques is lacking at the time of writing, and the goal of
kgrams is to fill this gap.
In the following Sections, I illustrate the prototypical workflow for
building a
-gram
language model with kgrams, show how to compute probabilities and perplexities, and (for the sake of fun!) generate random text at different temperatures.
Building a -gram language model
This section illustrates the typical workflow for building a
-gram
language model with kgrams. In summary, this involves the
following main steps:
- Load the training corpus, i.e. the text from which -gram frequencies are estimated.
- Preprocess the corpus and tokenize sentences.
- Store -gram frequency counts from the preprocessed training corpus.
- Build the final language model, by initializing its parameters and computing auxiliary counts possibly required by the smoothing technique employed.
We illustrate all these steps in the following.
Step 1: Loading the training corpus
kgrams offers two options for reading the text corpora
used in its computations, which are basically in-memory and
out-of-memory solutions:
-
in-memory. The corpus is simply loaded in the R session as
a
charactervector. -
out-of-memory. The text is read in batches of fixed size
from a
connection. This solution includes, for instance, reading text from a file, from an URL, or from the standard input.
The out-of-memory solution can be useful for training over large corpora without the need of storing the entire text into the RAM.
In this vignette, for illustration, we will use the example dataset
kgrams::much_ado (William Shakespeare’s “Much Ado About
Nothing”).
Step 2: preprocessing and tokenizing sentences
One can (and usually should) apply some transformations to the raw training corpus before feeding it as input to the -gram counting algorithm. In particular, the algorithm considers as a sentence each entry of its pre-processed input, and pads each sentence with Begin-Of-Sentence (BOS) and End-Of-Sentence (EOS) tokens. It considers as a word any substring of a sentence delimited by (one or more) space characters.
For the moment, we only need to define the functions used for
preprocessing and sentence tokenization. We will use the following
functions, which leverage on the basic utilities
kgrams::preprocess() and kgrams::tknz_sent(),
and perform some additional steps, since we will be reading raw HTML
lines from the URL connection created above.
.preprocess <- function(x) {
# Remove speaker name and locations (boldfaced in original html)
x <- gsub("<b>[A-z]+</b>", "", x)
# Remove other html tags
x <- gsub("<[^>]+>||<[^>]+$||^[^>]+>$", "", x)
# Apply standard preprocessing including lower-case
x <- kgrams::preprocess(x)
# Collapse to a single string to avoid splitting into more sentences at the end of lines
x <- paste(x, collapse = " ")
return(x)
}
.tknz_sent <- function(x) {
# Tokenize sentences
x <- kgrams::tknz_sent(x, keep_first = TRUE)
# Remove empty sentences
x <- x[x != ""]
return(x)
}Step 3: get -gram frequency counts
We can now obtain
-gram
frequency counts from Shakespeare with a single command, using the
function kgram_freqs(). The following stores
-gram
counts for
-grams
of order less than or equal to
:
freqs <- kgram_freqs(much_ado, # Read Shakespeare's text from connection
N = 5, # Store k-gram counts for k <= 5
.preprocess = .preprocess, # preprocess text
.tknz_sent = .tknz_sent, # tokenize sentences
verbose = FALSE
)
freqs
#> A k-gram frequency table.The object freqs is an object of class
kgram_freqs, i.e. a
-gram
frequency table. We can obtain a first informative summary of what this
object contains by calling summary():
summary(freqs)
#> A k-gram frequency table.
#>
#> Parameters:
#> * N: 5
#> * V: 3046
#>
#> Number of words in training corpus:
#> * W: 26123
#>
#> Number of distinct k-grams with positive counts:
#> * 1-grams:3048
#> * 2-grams:14373
#> * 3-grams:21201
#> * 4-grams:22705
#> * 5-grams:22974The parameter V is the size of the dictionary, which was
created behind the scenes by kgram_freqs(), using all words
encountered in the text. In alternative, we could have used a
pre-specified dictionary through the argument dict, and
specify whether new words (not present in the original dictionary)
should be added to it, or be replaced by an Unknown-Word (UNK) token, by
the argument open_dict; see ?kgram_freqs for
further details. The number of distinct unigrams is greater than the
size of the dictionary, because the former also includes the special BOS
and EOS tokens.
Notice that the functions .preprocess() and
.tknz_sent() we defined above are passed as arguments of
kgram_freqs()3. These are also saved in the final
kgram_freqs object, and are by default applied also to
inputs at prediction time.
The following shows how to query -gram counts from the frequency table created above 4:
# Query some simple unigrams and bigrams
query(freqs, c("leonato", "enter leonato", "thy", "smartphones"))
#> [1] 38 6 52 0
# Query k-grams at the beginning or end of a sentence
query(freqs, c(BOS() %+% BOS() %+% "i", "love" %+% EOS()))
#> [1] 206 0
# Total number of words processed
query(freqs, "")
#> [1] 26123
# Total number of sentences processed
query(freqs, EOS())
#> [1] 2219The most important use of kgram_freqs objects is to
create language models, as we illustrate in the next step.
Step 4. Build the final language model
kgrams provides support for creating language models
using several classical smoothing techniques. The list of smoothers
currently supported by kgrams can be retrieved through:
smoothers()
#> [1] "ml" "add_k" "abs" "kn" "mkn" "sbo" "wb"The documentation page ?smoothers provides a list of
original references for the various smoothers. We will use Interpolated
Kneser-Ney smoothing (Kneser and Ney 1995;
see also Chen and Goodman 1999), which goes under the code
"kn". We can get some usage help for this method through
the command:
info("kn")
#> Interpolated Kneser-Ney
#> * code: 'kn'
#> * parameters: D
#> * constraints: 0 <= D <= 1As shown above, Kneser-Ney has one parameter , which is the discount applied to bare -gram frequency counts or continuation counts. We will initialize the model with , and later tune this parameter through a test corpus.
To train a language model with the
-gram
counts stored in freqs, use:
kn <- language_model(freqs, "kn", D = 0.75)
kn
#> A k-gram language model.This will create a language_model object, which can be
used to obtain word continuation and sentence probabilities. Let us
first get a summary of our final model:
summary(kn)
#> A k-gram language model.
#>
#> Smoother:
#> * 'kn'.
#>
#> Parameters:
#> * N: 5
#> * V: 3046
#> * D: 0.75
#>
#> Number of words in training corpus:
#> * W: 26123
#>
#> Number of distinct k-grams with positive counts:
#> * 1-grams:3048
#> * 2-grams:14373
#> * 3-grams:21201
#> * 4-grams:22705
#> * 5-grams:22974The parameter D can be accessed and modified through the
functions parameters() and param(), which have
a similar interface to the base R function attributes() and
attr():
parameters(kn)
#> $N
#> [1] 5
#>
#> $V
#> [1] 3046
#>
#> $D
#> [1] 0.75
param(kn, "D")
#> [1] 0.75
param(kn, "D") <- 0.6
param(kn, "D")
#> [1] 0.6
param(kn, "D") <- 0.75We can also modify the order of the -gram model, by choosing any number less than or equal to (since we stored up to -gram counts):
param(kn, "N") <- 4 # 'kn' uses only 1:4-grams
param(kn, "N")
#> [1] 4
param(kn, "N") <- 5 # 'kn' uses also 5-gramsIn the next section we show how to use this language model for basic tasks such as predicting word and sentence probabilities, and for more complex tasks such as computing perplexities and generating random text.
Using language_model objects
So far we have created a language_model object using
Interpolated Kneser-Ney as smoothing method. In this section we show how
to:
- Obtain word continuation and sentence probabilities.
- Generate random text by sampling from the language model probability distribution.
- Compute the language model’s perplexity on a test corpus.
Word continuation and sentence probabilities
We can obtain both sentence probabilities and word continuation
probabilities through the function probability(). This is
generic on the first argument, which can be a character for
sentence probabilities, or a word_context expression for
continuation probabilities.
Sentence probabilities can be obtained as follows (the first two are sentences from the training corpus):
probability(c("Did he break out into tears?",
"I see, lady, the gentleman is not in your books.",
"We are predicting sentence probabilities."
),
model = kn
)
#> [1] 2.781389e-05 8.821088e-07 9.482178e-19Behind the scenes, the same .preprocess() and
.tknz_sent() functions used during training are being
applied to the input. We can turn off this behaviour by explicitly
specifying the .preprocess and .tknz_sent
arguments of probability().
Word continuation probabilities are the conditional probabilities of
words following some given context. For instance, the probability that
the words "tears" or "pieces" will follow the
context "Did he break out into" are computed as
follows:
probability("tears" %|% "Did he break out into", model = kn)
#> [1] 0.5813744
probability("pieces" %|% "Did he break out into", model = kn)
#> [1] 1.000375e-05The operator %|% takes as input a character vector on
its left-hand side, i.e. the list of candidate words, and a length one
character vector on its right-hand side, i.e. the given context. If the
context has more than
words (where
is the order of the language model, five in our case), only the last
words are used for prediction.
Generating random text
We can sample sentences from the probability distribution defined by
our language model using sample_sentences(). For
instance:
set.seed(840)
sample_sentences(model = kn,
n = 10,
max_length = 10
)
#> [1] "i have studied officers ; <EOS>"
#> [2] "truly by in your company thing that you ask for [...] (truncated output)"
#> [3] "i protest i love the gentleman is wise ; <EOS>"
#> [4] "for it . <EOS>"
#> [5] "the best befits can i for your own hobbyhorses hence [...] (truncated output)"
#> [6] "but by this travail fit the length july cham's beard [...] (truncated output)"
#> [7] "don pedro she doth well as being some attires and [...] (truncated output)"
#> [8] "exeunt all ladies only spots of grey all the wealth [...] (truncated output)"
#> [9] "heighho ! <EOS>"
#> [10] "exit margaret ursula friar . <EOS>"The sampling is performed word by word, and the output is truncated
if no EOS token is found after sampling
max_length words.
We can also sample with a temperature different from one. The temperature transformation of a probability distribution is defined by:
where is the partition function, defined in such a way that . Intuitively, higher and lower temperatures make the original probability distribution smoother and rougher, respectively. By making a physical analogy, we can think of less probable words as states with higher energies, and the effect of higher (lower) temperatures is to make more (less) likely to excite these high energy states.
We can test the effects of temperature on our Shakespeare-inspired
language model, by changing the parameter t of
sample_sentences() (notice that the default
t = 1 corresponds to the original distribution):
sample_sentences(model = kn,
n = 10,
max_length = 10,
t = 0.1 # low temperature
)
#> [1] "i will not have to do with you . <EOS>"
#> [2] "i will go before and show him their examination . [...] (truncated output)"
#> [3] "i will not be sworn but love may transform me [...] (truncated output)"
#> [4] "i will go get her picture . <EOS>"
#> [5] "i will go on the slightest errand now to the [...] (truncated output)"
#> [6] "i will not be sworn but love may transform me [...] (truncated output)"
#> [7] "i will not be sworn but love may transform me [...] (truncated output)"
#> [8] "and i will like a true drunkard utter all to [...] (truncated output)"
#> [9] "i will not be sworn but love may transform me [...] (truncated output)"
#> [10] "i will not be sworn but love may transform me [...] (truncated output)"
sample_sentences(model = kn,
n = 10,
max_length = 10,
t = 10 # high temperature
)
#> [1] "minds wants valuing peace speech libertines after offered being braggarts [...] (truncated output)"
#> [2] "smell fiveandthirty from possible knowest sickness tonight panders agony show'd [...] (truncated output)"
#> [3] "where's give intelligence princes finer tire scab brought rearward deserved [...] (truncated output)"
#> [4] "heart's evening virtues holds c hadst persuasion can finer churchbench [...] (truncated output)"
#> [5] "modesty thinks noncome remorse epitaphs consented mortifying whom hath expectation [...] (truncated output)"
#> [6] "impossible yielded deceive wedding mouth unclasp absentand qualify twelve giddily [...] (truncated output)"
#> [7] "certainly nightraven prized grief laugh claw invincible tyrant blessed run [...] (truncated output)"
#> [8] "senseless beat time denies 'hundred ten forth hire' reenter toothache [...] (truncated output)"
#> [9] "laughed civil kill'd mean hero's yea foundation deformed appetite hour [...] (truncated output)"
#> [10] "studied figure nine leonato enough ever herself confess authority sanctuary [...] (truncated output)"As explained above, sampling with low temperature gives much more weight to probable sentences, and indeed the output is very repetitive. On the contrary, high temperature makes sentence probabilities more uniform, and in fact our output above looks quite random.
Compute language model’s perplexities
Perplexity is a standard evaluation metric for the overall performance of a language model. It is given by , where is the cross-entropy of the language model sentence probability distribution against a test corpus empirical distribution:
Here is total number of words in the test corpus (following Ref. (Chen and Goodman 1999), we include counts of the EOS token, but not the BOS token, in ), and the sum extends over all sentences in the test corpus. Perplexity does not give direct information on the performance of a language model in a specific end-to-end task, but is often found to correlate with the latter, which provides a practical justification for the use of this metric. Notice that better models are associated with lower perplexities, and that is proportional to the negative log-likelihood of the corpus under the language model assumption.
Perplexities can be computed in kgrams using the
function perplexity(), which can read text both from a
character vector and from a connection. We
will take our test corpus again from Shakespeare’s opus, specifically
the play “A Midsummer Night’s Dream”, which is example data from
kgrams namespace:
midsummer[840]
#> [1] " when truth kills truth o devilishholy fray !"We can compute the perplexity of our Kneser-Ney
-gram
model kn against this corpus as follows:
perplexity(midsummer, model = kn)
#> [1] 376.3205We can use perplexity to tune our model parameter
.
We compute perplexity over a grid of values for D and plot
the results. We do this for the
-gram
models with
:
D_grid <- seq(from = 0.5, to = 0.99, by = 0.01)
FUN <- function(D, N) {
param(kn, "N") <- N
param(kn, "D") <- D
perplexity(midsummer, model = kn)
}
P_grid <- lapply(2:5, function(N) sapply(D_grid, FUN, N = N))
oldpar <- par(mar = c(2, 2, 1, 1))
plot(D_grid, P_grid[[1]], type = "n", xlab = "D", ylab = "Perplexity", ylim = c(300, 500))
lines(D_grid, P_grid[[1]], col = "red")
lines(D_grid, P_grid[[2]], col = "chartreuse")
lines(D_grid, P_grid[[3]], col = "blue")
lines(D_grid, P_grid[[4]], col = "black")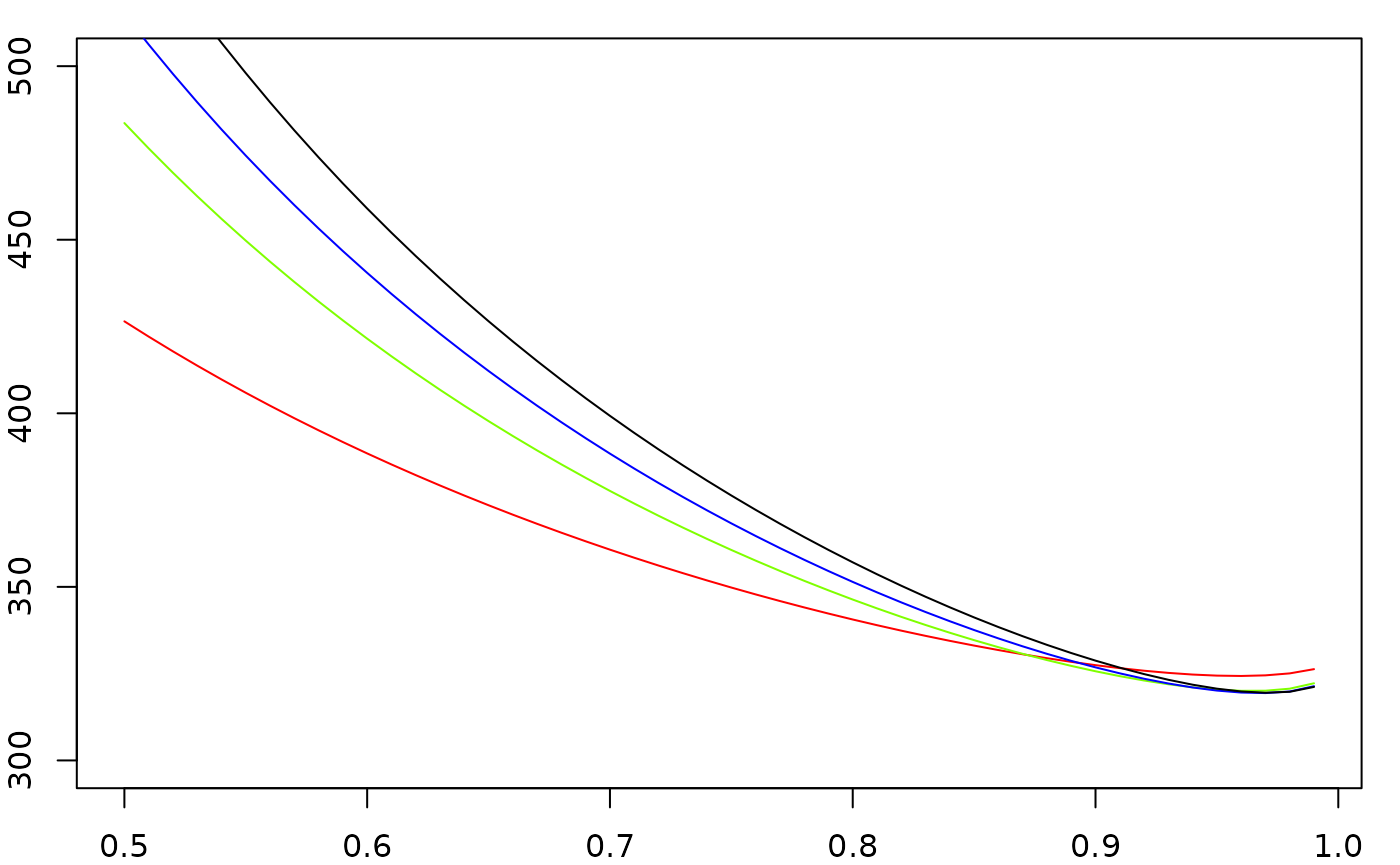
Perplexity as a function of the discount parameter of Interpolated Kneser-Ney 2-gram (red), 3-gram (green), 4-gram (blue) and 5-gram (black) models.
par(oldpar)We see that the optimal choices for D are close to its
maximum allowed value D = 1, for which the performance of
the 2-gram model is slightly worse than the higher order models, and
that the 5-gram model performs generally worse than the 3-gram and
4-gram models. Indeed, the optimized perplexities for the various
-gram
orders are given by:
sapply(c("2-gram" = 1, "3-gram" = 2, "4-gram" = 3, "5-gram" = 4),
function(N) min(P_grid[[N]])
)
#> 2-gram 3-gram 4-gram 5-gram
#> 324.3317 320.0537 319.4006 319.4984which shows that the best performing model is the 4-gram one, while it seems that the 5-gram model is starting to overfit (which is not very surprising, given the ridiculously small size of our training corpus!).
Conclusions
In this vignette I have shown how to implement and explore
-gram
language models in R using kgrams. For further help, you
can consult the reference page of the kgrams website. Development of
kgrams takes place on its GitHub repository. If you
find a bug, please let me know by opening an issue on GitHub, and if you
have any ideas or proposals for improvement, please feel welcome to send
a pull request, or simply an e-mail at vgherard840@gmail.com.
References
Here and below, when we talk about “language models”, we always refer to word-level language models. In particular, a -gram is a -tuple of words.↩︎
Perplexity is a standard evaluation metric for language models, based on the model’s sentence probability distribution cross-entropy with the empirical distribution of a test corpus. It is described in some more detail in this Subsection.↩︎
Strictly speaking, a single argument
.preprocesswould suffice, as the processed input is (symbolically).tknz_sent(.preprocess(input)). Having two separate arguments for preprocessing and sentence tokenization has a couple of advantages, as explained in?kgram_freqs.↩︎The string concatenation operator
%+%is equivalent topaste(lhs, rhs). Also, the helpersBOS(),EOS()andUNK()return the BOS, EOS and UNK tokens, respectively.↩︎