Text prediction via N-gram Stupid Back-off models
Valerio Gherardi
vgherard@sissa.it2020-12-05
Source:vignettes/sbo.Rmd
sbo.RmdIntroduction
The sbo package provides utilities for building and evaluating next-word prediction functions based on Stupid Back-off N-gram models in R. In this vignette, I illustrate the main features of sbo, including in particular:
- the typical workflow for building a text predictor from a given training corpus, and
- the evaluation of next-word predictions through a test corpus.
Building text predictors with sbo
Building a text predictor
In this and the next section we will employ the sbo::twitter_train example dataset1, each entry of which consists in a single tweet in English, e.g.:
head(sbo::twitter_train, 3)
#> [1] "FOX NEWS TODAY: \"Energizer Bunny Arrested, Charged With Battery!\""
#> [2] "Today is a good day! Excluding today, I only have 9 days of class left. Awww yeaaahh"
#> [3] "I will be at broadway bar tonight"Given the training corpus, the typical workflow for building a text-predictor consists of the following steps:
- Preprocessing. Apply some transformations to the training corpus before \(k\)-gram extraction.
- Sentence tokenization. Split the training corpus into sentences.
- Extract \(k\)-gram frequencies. These are the building blocks for any \(N\)-gram language model.
- Train a text predictor. Build a prediction function \(f\), which takes some text input and returns as output a next-word prediction (or more than one, ordered by decreasing probability).
Also, implicit in the previous steps is the choice of a model dictionary, which can be done a priori, or during the training process.
All these steps (including building a dictionary) can be performed in sbo as follows:
p <- sbo_predictor(object = sbo::twitter_train, # preloaded example dataset
N = 3, # Train a 3-gram model
dict = target ~ 0.75, # cover 75% of training corpus
.preprocess = sbo::preprocess, # Preprocessing transformation
EOS = ".?!:;", # End-Of-Sentence tokens
lambda = 0.4, # Back-off penalization in SBO algorithm
L = 3L, # Number of predictions for input
filtered = "<UNK>" # Exclude the <UNK> token from predictions
)This creates an object p of class sbo_predictor, which can be used to generate text predictions as follows:
predict(p, "i love")
#> [1] "you" "it" "my"Let us comment the various arguments in the previous call to sbo_predictor():
-
object. The training corpus used to train the text predictor. -
N. The order \(N\) of the \(N\)-gram model. -
dict. This argument specifies the model dictionary. In this case, we build our dictionary directly from the training corpus, using the most frequent words which cover a fractiontarget = 0.75of the corpus. In alternative, one can prune the corpus word set to a fixed vocabulary size, or use a predefined dictionary. -
.preprocess. The function used in corpus preprocessing. Here we leverage on the minimalsbo::preprocess, but this can be in principle any function taking a character input and returning a character output. -
EOS. This argument lists, in a single string, all End-Of-Sentence characters, employed for sentence tokenization (moreover, text belonging to different entries of the preprocessed input vector are understood to belong to different sentences). -
lambda. The penalization \(\lambda\) employed in the Stupid Back-Off algorithm. Here \(\lambda = 0.4\) is the benchmark value given in the original work by Brants et al.. -
L. Number of predictions to return for any given input. This needs to be specified a priori, because the objectpdoes not store the full \(k\)-gram frequency tables, but only a fixed number (i.e. \(L\)) of predictions for any \(k\)-gram prefix (\(k\leq N -1\)) observed in the training corpus. This is commented more at length below. -
filtered. Words to exclude from next-word predictions. Here the reserved string<UNK>excludes the Unknown-Word token (similarly, one can use the reserved string<EOS>to exclude End-Of-Sentence tokens).
Before proceeding, let us take a little break and introduce the most important function of sbo:
Out of memory use
The example in the previous Section illustrates how to use a text predictor in interactive mode. If the training process is computationally expensive, one may want to save the text predictor object (i.e. p in the example above) out of physical memory (e.g. through save()). For this purpose2, sbo provides the class sbo_predtable (“Stupid Back-Off prediction tables”).
These objects are a “raw” equivalent of a text predictor, and can be created with sbo_predtable(), which has the same user interface of sbo_predictor(). For example, the definition of p above would be replaced by:
t <- sbo_predtable(object = sbo::twitter_train, # preloaded example dataset
N = 3, # Train a 3-gram model
dict = target ~ 0.75, # cover 75% of training corpus
.preprocess = sbo::preprocess, # Preprocessing transformation
EOS = ".?!:;", # End-Of-Sentence tokens
lambda = 0.4, # Back-off penalization in SBO algorithm
L = 3L, # Number of predictions for input
filtered = "<UNK>" # Exclude the <UNK> token from predictions
)From t, one can rapidly recover the corrisponding text predictor, using sbo_predictor()3:
p <- sbo_predictor(t) # This is the same as 'p' created aboveObjects of class sbo_predtable can be safely stored out of memory and loaded in other R sessions:
Some details on sbo_predictor and sbo_predtable class objects
sbo_predictor and sbo_predtable objects directly store next-word predictions for each \(k\)-gram prefix (\(k=1,\,2,\dots,\,N-1\)) observed in the training corpus, allowing for memory compression and fast query.
Both objects store, through attributes, information about the training process. This can be conveniently obtained through the corresponding summary() methods, e.g.
summary(p)
#> Next-word text predictor from Stupid Back-off N-gram model
#>
#> Order (N): 3
#> Dictionary size: 1008 words
#> Back-off penalization (lambda): 0.4
#> Maximum number of predictions (L): 3
#>
#> See ?predict.sbo_predictor for usage help.
Internal structure of sbo_predictor and sbo_predtable objects
Here are some details on the current (still under development) implementation of sbo_predictor and sbo_predtable objects. For clarity, I will refer to the sbo_predtable instance t created above:
head(t[[3]])
#> w1 w2 prediction1 prediction2 prediction3
#> [1,] 4 749 1 68 33
#> [2,] 472 62 1 4 28
#> [3,] 98 288 1 4 5
#> [4,] 428 262 1 13 4
#> [5,] 193 17 1 415 1009
#> [6,] 333 738 1 1009 16The first two columns correspond to the word codes4 of \(2\)-gram prefixes observed in the training corpus, and the other columns code the top \(L=3\) predictions for these \(2\)-grams. When a \(2\)-gram \(w_1 w_2\) is given as input for text prediction, it is first looked for in the prefix columns of t[[3]]. If not found, \(w_2\) is looked for in the prefix column of t[[2]]. If this also fails, the prediction is performed without any prefix, that is, we simply predict the L most frequent words, stored in:
t[[1]]
#> prediction1 prediction2 prediction3
#> [1,] 1009 1 2Evaluating next-word predictions
This Section leverages, for convenience, on:
Once we have built our next-word predictor, we may want to directly test its predictions on an independent corpus. For this purpose, sbo offers the function eval_sbo_predictor(), which samples \(N\)-grams from a test corpus and compares the predictions from the \((N-1)\)-gram prefixes with the true completions.
More in detail, given a character vector test, where each entry of test represents a single document, eval_sbo_predictor() performs the following steps:
- Sample a single sentence from each entry of
test, i.e. from each document. - Sample a single \(N\)-gram from each sentence obtained in the previous step.
- Predict next words from the \((N-1)\)-gram prefix.
- Return all predictions, together with the true word completions.
For a reasonable estimate of prediction accuracy, the various entries of test should be independent documents, e.g. single tweets as in the sbo::twitter_test example dataset, which we use below to test the previously trained predictor p.
set.seed(840)
(evaluation <- eval_sbo_predictor(p, test = sbo::twitter_test))
#> # A tibble: 10,000 x 4
#> input true preds[,1] [,2] [,3] correct
#> <chr> <chr> <chr> <chr> <chr> <lgl>
#> 1 "come back" to to <EOS> and TRUE
#> 2 "amazing should" have post be have TRUE
#> 3 "u at" <EOS> <EOS> the next TRUE
#> 4 "they'll be" respected a with in FALSE
#> 5 " everyone" follow is should loves FALSE
#> 6 "luck this" weekend weekend season is TRUE
#> 7 "atlanta weather" is <EOS> in to FALSE
#> 8 "iphone 4s" just <EOS> the me FALSE
#> 9 "is it" working <EOS> that just FALSE
#> 10 "did you" listen know get see FALSE
#> # … with 9,990 more rowsAs it is seen, eval_sbo_predictor() returns a tibble containing the input \((N-1)\)-grams, the true completions, the predicted completions and a column indicating whether one of the predictions were correct or not.
We can estimate predictive accuracy as follows (the uncertainty in the estimate is approximated by the binomial formula \(\sigma = \sqrt{\frac{p(1-p)}{M}}\), where \(M\) is the number of trials):
evaluation %>% summarise(accuracy = sum(correct)/n(),
uncertainty = sqrt(accuracy * (1 - accuracy) / n())
)
#> # A tibble: 1 x 2
#> accuracy uncertainty
#> <dbl> <dbl>
#> 1 0.316 0.00465We may want to exclude from the test \(N\)-grams ending by the End-Of-Sentence token (here represented by "<EOS>"):
evaluation %>% # Accuracy for in-sentence predictions
filter(true != "<EOS>") %>%
summarise(accuracy = sum(correct) / n(),
uncertainty = sqrt(accuracy * (1 - accuracy) / n())
)
#> # A tibble: 1 x 2
#> accuracy uncertainty
#> <dbl> <dbl>
#> 1 0.184 0.00427In trying to reduce the size (in physical memory) of your text-predictor, it might be useful to prune the model dictionary. The following command plots an histogram of the distribution of correct predictions in our test.
if (require(ggplot2)) {
evaluation %>%
filter(correct, true != "<EOS>") %>%
select(true) %>%
transmute(rank = match(true, table = attr(p, "dict"))) %>%
ggplot(aes(x = rank)) + geom_histogram(binwidth = 25)
}
#> Carico il pacchetto richiesto: ggplot2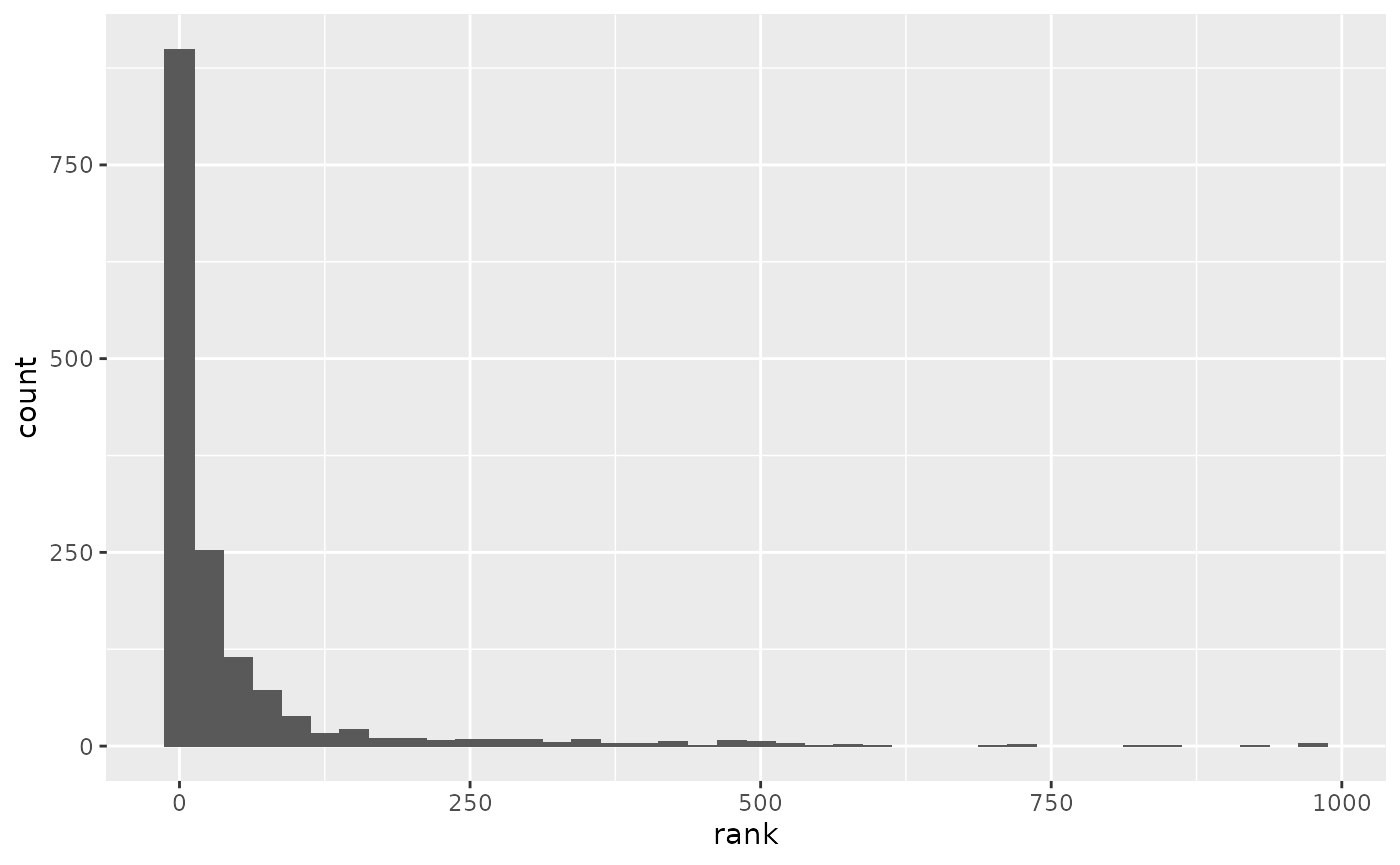
Apparently, the large majority of correct predictions come from the first ~ 300 words of the dictionary, so that if we prune the dictionary excluding words with rank greater than, e.g., 500 we can reduce the size of our model without seriously affecting its prediction accuracy.
Other functionalities
In this Section, I briefly survey other functionalities provided by sbo. See the corresponding help pages for more details.
Dictionaries
Dictionaries can be directly built using sbo_dictionary(). For example, the command:
dict <- sbo_dictionary(corpus = sbo::twitter_train,
max_size = 100,
target = 0.5,
.preprocess = sbo::preprocess,
EOS = ".?!:;")constructs a dictionary applying the most restrictive of the two constraint max_size = 100 or target = 0.5, where target denotes the coverage fraction of corpus. The arguments .preprocess and EOS work as described above.
The output is an object of class sbo_dictionary, which stores, along with a vector of words (sorted by decreasing frequency), also the original values of .preprocess and EOS.
Word coverage
The word coverage fraction of a dictionary can be computed through the generic function word_coverage(). This accepts as argument any object containing a dictionary, along with a preprocessing function and a list of End-Of-Sentence characters. This includes all sbo main classes: sbo_dictionary, sbo_kgram_freqs, sbo_predtable and sbo_predictor. For instance:
(c <- word_coverage(p, sbo::twitter_train))
#> A 'word_coverage' object.
#>
#> See summary() for more details.Computes the coverage fraction of the dictionary used by the predictor p, on the original training corpus.
This can be conveniently summarized with:
summary(c)
#> Word coverage fraction
#>
#> Dictionary length: 1008
#> Coverage fraction (w/ EOS): 78.2 %
#> Coverage fraction (w/o EOS): 75 %or visualized with:
plot(c)
\(k\)-gram tokenization
\(k\)-gram frequency tables form the building blocks of any \(N\)-gram based language model. The function sbo::kgram_freqs() extracts frequency tables from a training corpus and stores them into a class sbo_kgram_freq object. For example:
f <- kgram_freqs(corpus = sbo::twitter_train,
N = 3,
dict = target ~ 0.75,
.preprocess = sbo::preprocess,
EOS = ".?!:;"
)stores \(k\)-gram frequency tables into f. This object can itself be used for text prediction:
predict(f, "i love")
#> # A tibble: 1,009 x 2
#> completion probability
#> <chr> <dbl>
#> 1 you 0.222
#> 2 it 0.0573
#> 3 my 0.0549
#> 4 the 0.0524
#> 5 your 0.0312
#> 6 this 0.0312
#> 7 that 0.0287
#> 8 how 0.0249
#> 9 u 0.0175
#> 10 when 0.0150
#> # … with 999 more rowsThe output contains the full language model information, i.e. the probabilities5 for each possible word completion. Compare this with:
predict(p, "i love")
#> [1] "you" "it" "my"The extra information contained in f comes at a price. In fact, the advantage provided by sbo_predictor/sbo_predtable objects for simple text prediction is two-fold:
- Memory compression:
size_in_MB <- function(x) format(utils::object.size(x), units = "MB")
sapply(list(sbo_predtable = t, kgram_freqs = f), size_in_MB)
#> sbo_predtable kgram_freqs
#> "1.4 Mb" "4.7 Mb"- Fast query:
chrono_predict <- function(x) system.time(predict(x, "i love"), gcFirst = TRUE)
lapply(list(sbo_predictor = p, kgram_freqs = f), chrono_predict)
#> $sbo_predictor
#> user system elapsed
#> 0 0 0
#>
#> $kgram_freqs
#> user system elapsed
#> 0.129 0.000 0.128Text preprocessing
Usually text corpora require preprocessing before word and \(k\)-gram tokenization can take place. The .preprocess argument of kgram_freqs() allows for an user specified preprocessing function. The default is the minimal sbo::preprocess(), and the optimized kgram_freqs_fast(erase = x, EOS = y) is equivalent to kgram_freqs(.preprocess = sbo::preprocess(erase = x, EOS = y)) (but more efficient).
Sentence tokenization
Tokenization at the sentence level is required to obtain terminal \(k\)-grams (i.e. \(k\)-grams containing Begin-Of-Sentence or End-Of-Sentence tokens). In the training process, sentence tokenization takes place after text preprocessing.
End-Of-Sentence (single character) tokens are specified by the EOS argument of kgram_freqs() and kgram_freqs_fast(); empty sentences are always skipped. Also, if the input vector text has length(text) > 1, the various elements of text belong to different entries.
The process of sentence tokenization can also be performed directly, through sbo::tokenize_sentences(), but this is not required for use with kgram_freqs*().
This is a small samples of \(5·10^4\) entries from the “Tweets” Swiftkey dataset fully available here.↩︎
At the present stage of development, this cannot be done directly for the
sbo_predictorobject created above. Technically, this is becausesbo_predictorobjects are external pointers to a convenient C++ class, optimized for fastpredict()ions. Such a class instance exists only during a single R session.↩︎As this example makes clear, both
sbo_predictor()andsbo_predtable()are S3 generics. The corresponding available methods are listed under?sbo_predictions.↩︎Coded with respect to the rank sorted dictionary
dict(the codes0,length(dict) + 1andlength(dict) + 2correspond to the Begin-Of-Sentence, End-Of-Sentence and Unknown-Word tokens, respectively).↩︎More precisely, these are the normalized (to unity) scores resulting from the Stupid Back-Off smoothing method.↩︎